cPanel WordPress Backup: A Practical Guide for Virtual Host Owners
Introduction
If you manage your own virtual host, you need a cPanel WordPress backup strategy. While you can configure cPanel a ferw ways to automated backups, eventually the truth is that using Secure Shell (SSH) is more direct. It also affords maximum flexibility when restoring content.
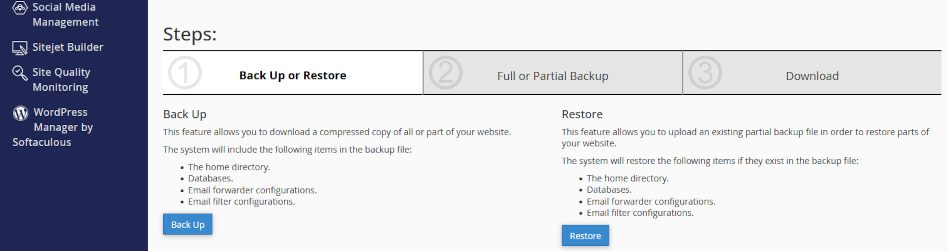
For instance, Softaculous and other third party backup utilities impose attributes during backup/export that can obstruct access to files during restoration.
Instead, cPanel’s CLI (Command Line Interface) provides means to rename directory/file ownership and avoid WordPress ID codes that can render backups unusable. This guide shows you how to back up and restore your WordPress site, database, and (optionally) email quickly and reliably.
Important: this article gives an overview of a backup procedure assuming conventional configurations. You may need to tailor this workflow according to your virtual host’s LAMP, PHP, WordPress (or nested WordPress), and MySQL versions. If in doubt, you should contact us especially for production web sites for professional help.
Click open the headers below to learn more about using simple command line instructions to secure maximum flexibility for data restoration. Support options are available for professional assistance. You can return to our Index of Articles by clicking here.
What You Need Before You Start
To follow this cPanel WordPress backup workflow, you will need:
- SSH access to your server
- Your cPanel username and password credentials
- Basic command-line familiarity
- Permission to run backup commands
You may need to contact us for SSH access. SSH is usually restricted for improved security, and we are happy to enable it should you want SSH on an ongoing basis.
Step 1: Back Up WordPress Files
Your WordPress site lives in the public_html directory in your server’s home directory. Use this command to create a compressed archive:
tar -czf /home/username/public_html.tar.gz -C /home/username public_html
This creates a clean file backup that includes:
- Themes
- Plugins
- Media uploads
- Configuration files
This is the first part of your cPanel WordPress backup process.
Step 2: Back Up your WordPress Database
WordPress stores your web site’s content in a MySQL database. Credentials for your database are stored “server side” in a WordPress file called wp-config.php. You can open this file with a text editor to make a note of these credentials:
- DB name
- DB user
- DB password
Next, using your SSH command line, run this command:
mysqldump -u dbuser -p dbname > /home/username/database.sql
This database dump contains:
- Posts and pages
- Users
- Site settings
You can alternately export the database using phpMyAdmin. This is another efficient option, and it is secure because the database “dump” is downloaded to your local workstation.
Step 3 (OPTIONAL) Back Up Email
Email is stored separately from your website. Usually, email is handled via Microsoft 365, Gmail, or another email service. If you manage email via your web server, though, you need to back up your email. To capture this content use:
tar -czf /home/username/email.tar.gz -C /home/username mail etc
This captures:
- Mailboxes and messages
- Email account configuration
You can back up all accounts at once or target individual mailboxes if needed.
Step 4: Store Your Backups Safely
Once created, download your backups or move them to a safe location. For example:
scp username@server:/home/username/*.tar.gz ./
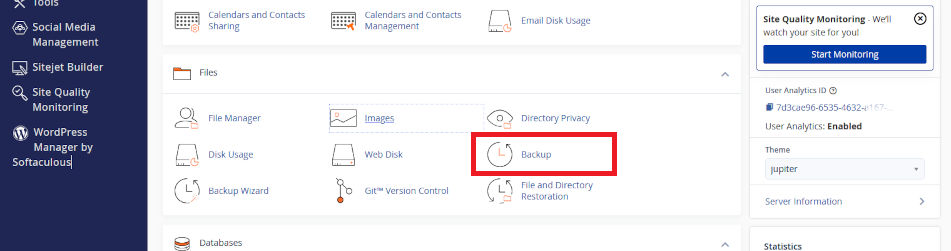
This command copies files from the server to your local machine. You can use cPanel File Explorer to do the same thing. Sometimes, using a mouse is a more familiar way to deal with files. Either way, keeping copies off the server ensures you can recover even if the original host fails.
Restoring your WordPress site
There are a few reasons backups are useful:
- you want to restore a last known working condition
- you want to migrate your web site to a new web server
- you may need to re-house your web site using a different domain name
Using Linux commands using cPanel’s SSH access is the only way to allow these eventualities to happen.
Restore your WordPress site
This cPanel WordPress backup workflow makes recovery simple. If you are restoring files to your existing server, skip to step 2.
- Recreate the cPanel Account
- Set up a new account with the same username if possible.
- Restore WordPress Themes/Plugins/Admin files
- tar -xzf public_html.tar.gz -C /home/username
- Restore Database
- mysql -u dbuser -p dbname < database.sql
- Fix Permissions
- chown -R username:username /home/username/public_html
- Check configuration
- Ensure wp-config.php matches the database details.
Restore email (optional)
If you included email in your cPanel backup WordPress process:
- Recreate email accounts in cPanel
- Restore files:
- tar -xzf email.tar.gz -C /home/username
- Reset permissions:
- chown -R username:mail /home/username/mail
Mail clients should then resynchronise automatically.
Why This Method Works Well
There are a few ways to backup a WordPress installation. Most methods become problematic because of limitations that backup utilities offer. Sometimes, this is to suit a limited purpose in the first place. This cPanel WordPress backup approach gives you:
- Independence from cPanel restore tools
- Fast, lightweight backups
- Full control over restoration
- including file naming
- ignoring WordPress ID codes that might prohibit import
- renaming and credentialling WordPress databases
- Clean rebuilds without legacy issues
Summary
A manual cPanel WordPress backup workflow using SSH is simple, reliable, and efficient. It suits users who want clarity and control during migrations or recovery.
Used alongside standard cPanel tools, our cPanel WordPress backup workflow gives you both flexibility and peace of mind.
If you need help adopting this workflow, or you need disaster recovery planning or assistance, please get in touch, or use our contact page to organize an appointment which suits your timetable. You can return to our Index of Articles by clicking here .